 | |
|
Soumen Chakrabarti1 - David A. Gibson2 - Kevin S. McCurley3
Life can only be understood backwards, but it must be lived forwards. |
From a user's perspective, hypertext links on the web form a directed graph between distinct information sources. We investigate the effects of discovering ``backlinks'' from web resources, namely links pointing to the resource. We describe tools for backlink navigation on both the client and server side, using an applet for the client and a module for the Apache web server. We also discuss possible extensions to the HTTP protocol to facilitate the collection and navigation of backlink information in the world wide web.
Hypertext predecessors to the world wide web such as Xanadu4 were conceived as bidirectional in nature, requiring the authors of both resources to create links between the two. Such a system promotes a uniform and consistent set of hyperlinked documents, but inhibits the modern scientific tradition of open criticism and debate. A large part of the intellectual value of the web is derived from the fact that authors of web documents can freely link to other documents in the namespace without agreement from the author of the referenced document. Placing a document into the namespace implicitly implies an ability to link to that document, and this is part of the reason that the web has grown so explosively.
Scientific literature has traditionally built on the body of knowledge that preceded it, and the notion of citation has become a fundamental part of scientific writing. By following citations, the reader is able to trace backward in time through the evolution of ideas that leads to the current work. Unfortunately, this system is unidirectional, and does not allow the reader to trace forward in time. Such a facility is provided as a commercial service by the Scientific Citation Index5 and the Web of Science6 from Information Sciences Institute. Using the Science Citation Index, a reader can follow citations of earlier scientific work, and move forward in time through the scientific literature.
In the context of the world wide web, we call such a reverse citation a backlink. Backlinks are seldom used in the world wide web, but we believe that they add significant value to the process of information discovery. Through the use of our tools we have discovered many unusual ``nugget'' sites that are not easily discovered by tracing forward along the edges of the web graph, but are quickly located by traversing the links in the reverse direction. Following backlinks can often lead to information that has been created more recently, and may therefore provide an important improvement to the timeliness of information discovered on the web. As the web matures over time, we expect this factor to increase in importance.
Backlinks enjoy an advantage over automated ``find similar resources'' mechanisms because they are human-created. Other techniques, such as HITS [10], have already exploited this fact to great success. Page creation is by and large a personal authoring process, and creating links involves quite some deliberate effort and judgement, certainly far more than any automated system can dream of doing for the foreseeable future. The reason for creating the link might vary from comment to compilation to criticism, but if the author has some standard of quality, there is always some relevancy.
Both HITS and backlink browsing are greatly aided by hub resources, which are compiled lists of relevant links on particular topics. If a site is respected enough to appear on one such resource list, one can find a list of similar resources with a single backlink traversal. This is probably the most useful backlink browsing technique. If backlink browsing became more commonplace, we would expect that commentary and criticism resources would become much more effective and numerous as well.
The effort required to maintain simple backlinks is minimal. Search engines provide a reasonably effective backlink database already. As discussed in the remainder of this paper, server maintainers can provide a more complete and up-to-date database very easily, and greatly enhance the usefulness of their sites. In effect, a resource can increase in quality without its creator's intervention, by the efforts of people authoring related resources.
This combination of forces leads us to believe that a significant enhancement of the world wide web can be achieved through backlink navigation. We propose simple extensions to the HTTP protocol to facilitate navigation through backlinks. We have implemented these facilities in a Java applet to augment existing clients, and have also built a module to support backlink retrieval from the popular Apache web server. These are not the only tools that one might imagine to facilitate backlink navigation, but provide the basis for building a cooperative infrastructure for open dialog. In section 3 we describe our simple extensions to the HTTP protocol. In section 4 we describe the design of the Apache module for the Apache web server.
A more scalable solution for both clients and servers is to leverage the existence of the Referer request-header. If servers recorded backlink information from the Referer request-header, then clients could retrieve backlink information directly from the server of the target resource. This has the advantage that it decentralizes and balances the load of backlink browsing, and leverages the existing practice of providing Referer request-header information.
For example, many commercial sites are unlikely to provide unfiltered backlink information, since they often have a different motivation in their publication, and are more strongly interested in controlling the message. Government sites may also be hostile to the idea of divulging information that criticizes government policies expressed on their web pages. Moreover, the ability to freely link to a document is not universally accepted, and some sites filter access to resources on the basis of the Referer header. There is no mechanism that can compel an author to acknowledge opinions or citations that they disagree with, and we see no conflict in this. We do not advocate any form of coerced compliance for building a backlink navigation capabilities, but expect it to emerge through a combination of balancing forces in society.
The reason for our optimism is that, while some sites may consider it counter to their interests to supply backlinks to their resources, other sites may leap at the opportunity. For example, the League of Women Voters considers it their mission to encourage citizen participation in the government process, and may therefore offer a ``portal site'' providing backlinks to government sites. Consumer's Union (publisher of Consumer Reports magazine) offers noncommercial product information for consumers, and backlink information for commercial sites might well be viewed as providing consumer information. Such a service might even be purchased by the client or supported by advertising.
Since a resource's backlinks provide a public ``place'' for people to comment, backlinks can be abused like many other public information channels. If a simple-minded approach is used to compile backlink information, then it becomes vulnerable to a form of ``spamming'', where a target site is induced to show a backlink to another site. In the case of backlinks, there are a variety of deterrence measures that can easily inhibit such attacks without requiring human management of the backlink mechanism. This is related to the problem of how to manage a backlink infrastructure, and we will return to the topic in section 4.
Intranets isolated by firewalls are also vulnerable to leaks through the Referer field. For example, at one time there existed a link from inside the FBI firewall to DigiCrime, and this fact was discovered by mining the log files (the author was unable to access the page). If there was an internal Sun web page with the URL w3.sun.com/javaos/parallel/99plan.htm, and if this resource linked to a competitor web site, then the mere transferrence of the Referer field in the HTTP protocol may leak the existence of a plan for deploying a parallel version of JavaOS in 1999 (there is no such plan that we are aware of). By making backlink information publicly available, our extensions may accelerate the leakage of such information. Luckily there is a simple solution for corporate intranets - namely to configure firewall proxy servers to remove or modify any Referer headers from internal sites. Another alternative is to use only browsers that follow the recommendation of RFC 2068 [13] to allow the user to control when Referer information is transmitted, in much the same way that the user is commonly allowed to control cookies. This recommendation is currently ignored by most popular browsers.
On the public web, the privacy impact of sending the Referer field is limited to those sites that are not linked from other resources. Creators of documents may expect their resource to remain private because they do not advertise it or provide links to it from other public resources. Such ``security by obscurity'' will be further degraded by the propagation of backlinks, but access control measures already exist to counter this.
Hypertext has been around since the Talmud and the Ramayana, if not earlier. There have been several bidirectional hypertext systems proposed, dating back at least to the time of the Xanadu project [23]. Other examples include DLS [9], Atlas [26], HackLinks [29], and Hyperwave [20]. References on hypertext systems can be found in [5,11]. More recently, the Foresight Institute has revived interest in the use of backlinks in hypertext publishing systems [16].
We can only speculate why these architectures have not become immensely popular on the web. Most likely, they were far ahead of their time, long before even the early days of standardizing, implementing and extending web protocols and markup languages. Storage costs may have been a barrier, or perhaps the small size and narrow interest in the web made it easier to locate resources at that time.
Today, the classification and organization of information on the web is a major problem for researchers seeking out specific information. Several researchers have previously suggested that an increased use of metadata will help in this direction, but retrofitting this information to the existing web is very challenging. Backlinks from a resource can be viewed as a form of dynamic metadata about the resource. There are several mechanisms that either exist already or are in the planning stages to support the use of metadata for web resources. These include the evolving HTML specification, the Resource Description Framework (RDF) [3], XML, WebDAV [14], and the Dublin Core Metadata Initiative [6].
Backlinks can also be used to bootstrap the effectiveness of other metadata. One of the problems identified by Marchiori [19] was the back-propagation of metadata, in which metadata from two objects may be merged if one provides a link to the other. A significant proportion of the existing web will lack metadata for the foreseeable future, but the ready availability of backlink information could be used to fill in these gaps across resources that don't incorporate metadata.
As a means of conveying backlink information to clients, HTML is deficient for several reasons. The HTML LINK element describes a relationship between the current document and another document. Unfortunately, there was no LinkType defined for ``is referenced by'', and the closest one in the DTD is ``prev'', for use in an ordered set of documents. We could easily extend this to include a ``back'' LinkType indicating knowledge of a link from that document to the current document. HTML 4.0 also specifies a way to insert META tags into the head of a document, and this could be used to store and transmit backlink information. There is no formal specification of how these should appear in documents, and documents have tended to implemented them in an ad-hoc manner that is consistent only within an organization.
Probably the biggest obstacle to conveying backlink information through the destination document is the fact that most of the documents that currently exist in the world wide web consist of static documents residing in file systems, and mere insertion of metadata is not enough. Much of the metadata (in particular, backlinks) is dynamic and requires a management infrastructure to update it. Moreover, many (if not most) of the existing resources have been abandoned by their authors, but the information retains value. Updating these resources will require a signficant effort to retrofit them with appropriate metadata.
Finally, it should be pointed out that a significant amount of information on the world wide web is contained in other data formats besides HTML. Some of these data formats now support external hypertext links. Examples include XML, PDF, FrameMaker, WinHelp, and Lotus Notes. Extracting consistent metadata from all of these sources will prove problematic. We therefore believe that the predominant method for transporting metadata in the near term will be external to the retrieved resource. We will return to this in section 3.
RDF does not address the problems of discovery and retrieval of backlink metadata. Retrieval is addressed in part by WebDAV and DASL, but discovery from multiple sources seems to be mostly overlooked. WebDAV supports retrieval of metadata as a subset of a much more ambitious effort to support distributed authorship of web resources. The design goals of WebDAV (see [27]) include support for locking, versioning, collections, remote editing, and namespace manipulation. The current draft includes new HTTP methods called PROPFIND and PROPPATCH to support retrieval and update of metadata about a resource. There are several potential barriers to rapid adoption of the WebDAV protocol, including potential security risks for servers.
Another thing that is not addressed by WebDAV is the ability to make queries on metadata. This is addressed in the DAV Searching and Locating (DASL) [4] protocol, which is a proposed extension to HTTP using XML. Among other things, this allows the specification of simple queries on DAV data. We expect WebDAV and DASL to play a significant role in the manipulation of backlink metadata.
It is not our goal to address the general design of a management system for backlink metadata, primarily because the specific goals behind metadata vary according to whose interests are being served. Users may wish to consult multiple sources of backlink information, and may wish to promote the free exchange of link information. Authors may not wish to provide pointers to things they do not agree with. Sites that wish to control the quality of backlink information more tightly, or exercise some editorial control on backlink information may choose to institute a labor-intensive human editing process on metadata (although backlink information could also be incorporated into the resources themselves). Third parties may wish to supply backlinks for their own purposes about resources they do not own. Supporting all of these will require a diverse set of tools. Our goal is simply to demonstrate that backlinks have value for information discovery, and describe the design of some basic tools to exploit them.
One of the primary reasons for the widespread success of hypertext beyond FTP and Gopher is the availability of an effective graphical user interface for users to navigate through the web. In order for backlinks to become a useful augmentation to the existing world wide web, there will have to be a widely deployed integration of the information into the user interface.
We are certainly not the first to have suggested displaying information related to the graph structure of the web within the browser. Many programs called site mappers have been developed that perform site-level crawls to help administrators maintain links. One example is Mapuccino from IBM Haifa [17]. These have been generalized and made more sophisticated. Miller and Bharat [21] have designed a system called SPHINX which is a customizable crawler which analyzes and presents sections of websites in a graphical format.
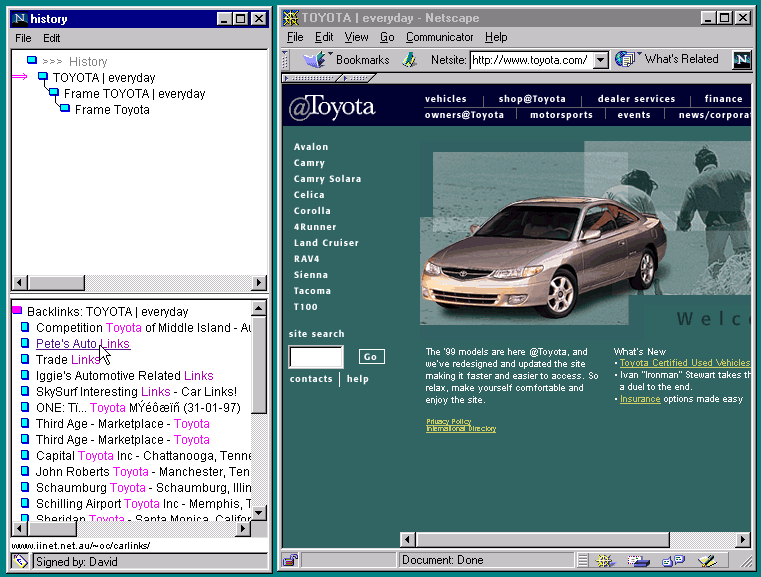
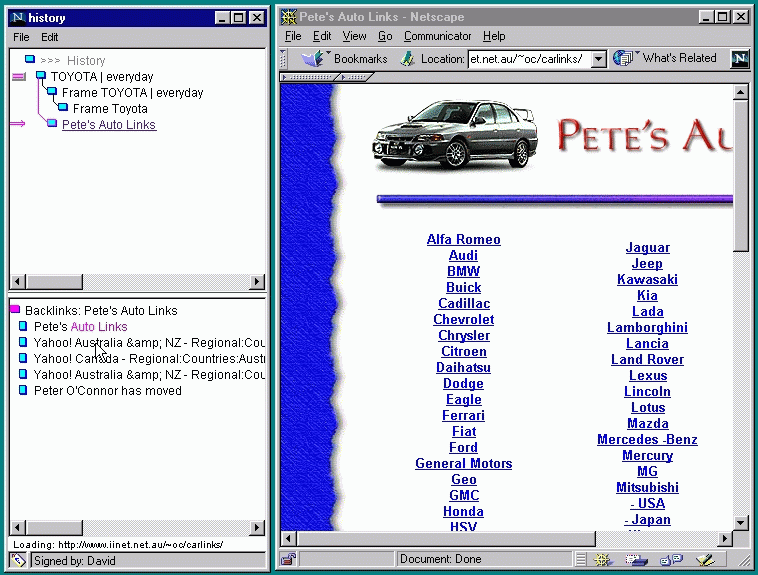
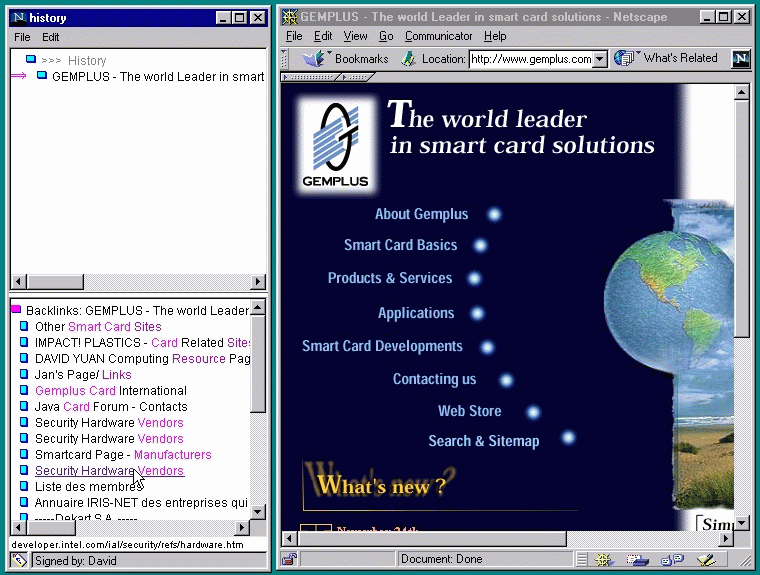
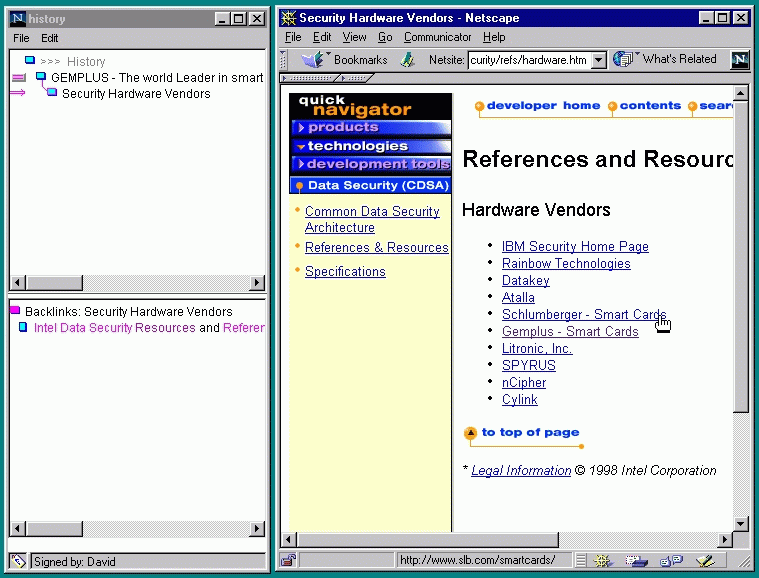
In this section we describe our experiences in implementing the ``browse assistant'' applet. We currently have a version working with Netscape Communicator version 4.07 or 4.5. We wrote the applet to study the effect of backlink guidance on the browsing activity and experience, and as a proof-of-concept prototype of the client end of our architecture proposal. Currently the browse assistant consults a search engine such as HotBot to retrieve backlink information. Views of the browser assistant are presented in Figures 1-2.
Due to the wide variety of applications and cultures present on the web, it is a difficult task to cater to all users in the transparently simple way that forward hyperlinking does. This makes the client design particularly tricky. The information has to be presented in as useful a way as possible, while being as universal as possible, and of course staying within the realm of feasible technology.
For this reason we designed the client in as general a fashion as possible, to make it useful in the widest variety of contexts. Of course, task-specific additions to this basic framework (such as finding related news stories, or having more sophisticated navigation controls) would improve it in specific contexts. But it has been our experience that a generic display has considerable use on its own.
The guiding principle in the client design is to provide context for the user browsing the web. Studies have shown that browsing the web is most strongly visualized with spatial metaphors [18], and context is best thought of in these terms: your context is ``where you are'' and where you are able to go next.
Web browsing is seldom a simple forward progression of link clicks: one often backtracks and explores new paths. However, the current generation of browsers show only the current page, and its outgoing links, as context. Our client expands this context in a natural way by making it easy to access pages you have visited recently, and by providing the backlink information.
Thus the two main interface panels are a history view, which shows recent browsing context, and the backlink view, which lists the backlinks of the currently displayed ``target'' page, showing the context of the target page in the larger compass of the web. The history view is displayed in a tree-like fashion to respect the backtracking nature of web exploration. The backlink view is a simple list of page titles. While the page title is not always the most informative description of a page, it is the most easily accessible and is, most often, sufficiently useful. Navigation is simple: the titles in both panels behave like conventional hyperlinks, and load the page into the main browse window. Buttons to the left of the history tree let one view the backlinks of other pages in the tree.
At present only a maximum of 25 backlinks are displayed: this is partly a technical limitation, but one does find that most pages have fewer backlinks than this, so this number is sufficient. The backlinks are ordered by a simple heuristic: they are scored according to how many words in the backlink title appear in the target page, and sorted by this score. This works well at bringing good pages to the top of the list, without incurring the overhead of fetching the backlink pages themselves.
Of course, this prototype design has room for many enhancements. One might want to specify filters on what type of backlinks are displayed. One could add annotations and persistent storage to the history view, to build a bookmarking scheme. One could arrange for custom information to be displayed in place of simple backlink titles, or give the target page designer greater control over the form and content of the backlinks.
This design has been received favourably by early users. One interesting observation was that there seem to be two distinct ways of visualizing browsing activity: some users thought of it as a kind of backtracking tree-search, and some imagined it more as a ``path in the woods''. Both viewpoints are valid, and we now include a feature to flatten the history tree, for users who prefer to browse linearly.
| |
|
 | |
|
 | |
|
 | |
|
We considered the following features such a browse assistant should ideally have. It should work with many browsers, since we don't want to have to recode it multiple times. It should be easy to install, without a hacked-up browser or patches. A plug-in is easier, but many users resist them. This led us to consider using Java. The assistant should also have a minimal performance impact on the client and the network.
The applet architecture is largely straightforward, but a few points should be made about the implementation details. The interface coding was constrained to be as lean as possible to speed loading times. We chose not to use Swing or other GUI toolkits, because the current generation of browsers does not include them by default. The applet performs several tasks which the Java default security model would disallow. It needs to be able to monitor the current browser window for new pages being loaded, fetch results from a search engine, and, for study purposes, we log the browse trail to local disk. In order to permit these operations, the applet must first be signed with a key certified by a trusted certification authority (CA) in order to certify authenticity. If the signature on the applet cannot be traced from a certificate in the browser, then it fails to run. For the purposes of our testing, we chose to produce our own self-signed certificate, and have the users download this as well. Once the applet starts, Netscape prompts the user for permission to perform the necessary operations. Similar mechanisms exist with Microsoft Internet Explorer, although the programming APIs are different and we restricted ourselves to a single implementation.
When the applet starts, it creates a new window, which should be used for further browsing. This means that the applet can continue to run uninterrupted in its own window, and that it can monitor the new window's browsing activity. Netscape's current model cannot send events to Java when a page is loaded, so the applet polls, by examining the contents of JavaScript variables. The applet can be configured to fetch backlinks from HotBot or AltaVista. An appropriate query string is formed, to minimize the amount of extraneous text returned, and the URLs and page titles are extracted from the engine results. Eventually it could also be configured to consult properly configured servers (see section 4).
In order to get some feel for the usefulness of backlinks, we designed a user experiment. Given the space of possible information needs and the diversity of the web as well as web users, the results should be regarded as anecdotal rather than rigorous. We picked eight topics for exploration by our volunteers. Topics were chosen to have a sizable supporting community and yet narrow enough that some human browsing would likely be required over and above keyword searches and/or topic distillation [10]. The topics chosen were ``Airbag safety'', ``Curling equipment'', ``vintage Gramaphone equipment'', ``Lyme disease'', ``Leonid meteor shower'', and ``freedom of Press''. They were made available to our volunteers on the web, along with a longer description for each of the topics. 8
Each volunteer was assigned randomly to two of the topics. Volunteers were given two versions of the backlink applet. One version (the placebo) did not show backlinks; the other did. The placebo applet only showed the tree-structured history view. For each topic we wanted at least one user to use the placebo applet and at least one user to use the full applet. We wanted to make the look-and-feel uniform and only test the value of backlinks.
Each volunteer had to first search for one topic using the placebo applet. They would enter the search terms above to Alta Vista, then browse for 15 minutes, then stop and send us a log of all URL's visited as maintained by the applet. Then they would use the backlinked version of the applet, searching for the second topic for 15 minutes.
A Perl script stripped off the information as to which version of the applet each URL came from, and produced an evaluation form, available on the web. 9 Three additional volunteers independently rated each URL without knowing the source applet version, on a scale of 0 to 3. They were instructed to visit the logged URL, and visit links on that page only if needed. The rating guideline was as follows:
| Topic | Forward | Backlink | Both |
| Airbag Safety | 22 | 148 | 11 |
| Curling equipment | 68 | 42 | 5 |
| vintage Gramaphone equipment | 10 | 112 | 2 |
| Lyme disease | 34 | 22 | 14 |
| Leonid meteor shower | 54 | 131 | 11 |
| freedom of Press | 65 | 24 | 3 |
| Total | 253 | 479 | 46 |
From these results it seems reasonable to conclude that for some topics, the incorporation of backlink navigation into a browser produces measurable improvement in the quality of information discovered on the web. In our experience, topics broader than our selection gave more useful results, as in the two examples shown in this paper.
We considered several different methods for integrating the retrieval of backlink information into the browsing process. It could be delivered inline to the normal browsing process, or as a separate document retrieval. If delivered inline, it could be piggybacked on the normal HTTP [7,13] process using keepalive to retrieve another document, or it could be delivered as part of a MIME multipart document, or it could be delivered in the HTTP response header. A client that wishes to take advantage of backlink information could express a willingness to receive the information in an Accept: header line, or negotiate the content that is delivered as in RFC 2295 [15]. None of these seem appropriate.
The original HTTP protocol [7] contained a method called ``LINK'' that was apparently intended for distributed maintenance of backlinks between resources. In addition, the Link: entity-header [13, Section 19.6.2.4] was suggested as a mechanism to convey backlink metadata in responses. The description sounds rather close to what we require, but unfortunately both were declared as experimental and unreliable in the HTTP 1.1 specification [13, Section 19.6]. As such they are now inappropriate foundations upon which to build.
Two more serious objections to the Link: entity-header are that it can degrade the performance of HTTP, and it fails to address several desirable features of backlink metadata. In particular, there is no transfer of ranking, freshness, or history data, and there is no way to issue queries on backlink metadata. The performance problem derives from the fact that backlink information is transferred in the header before transferring the actual resource body. Backlink metadata should properly be regarded as a secondary source of information about the resource, and fetching the metadata before fetching the resource is inefficient. Consider for example that HotBot already reports that it knows about 522,890 links to Yahoo!
WebDAV and RDF offer some attractive capabilities, but address far more than we needed and have a few drawbacks. In order to integrate the variety of sources that are available to clients and proxies, we chose to design an extension to HTTP that avoids some of these problems. Servers and clients that support WebDAV will be unaffected by the protocol we suggest.
Here each 15-location line indicates a MIME type and URI location for retrieving backlink information in that form. The URIs can be relative or absolute, to support both fetching the information from another site as well as from the server itself. The number 15 is merely an example, since it is dynamically generated by the server to avoid header conflicts as per [25]. The URIs should not be pointers to generic backlinks page, but rather should be specific to the page that was requested in the HTTP request.Opt: "http://www.swcp.com/~mccurley/bl/"; ns=15- 15-location: text/html URI1 15-location: text/rdf URI2
If the client and server are using persistent connections, the client can go ahead and issue the request for backlink information into the pipeline as soon as they see the appropriate response-header indicating that backlinks are available. This streamlines the retrieval. If the client and server are not using persistent connections, or if the backlink information is to be retrieved from a different server, then a separate connection will have to be initiated by the client.
In our example, we gave two locations for backlink information, with two different MIME types for the content at those locations. The option of providing information in several forms is designed to support both collection by machine and interaction by humans. The text/html MIME type is intended for humans to view, and tailor their access to backlink information. This gives the server control over the display, search, access control, and policy. It may contain simply an HTML-formatted list of inlinks, or it may also contain a query interface for how to request links to the page. For example, a server may offer a query interface for requesting only inlinks from certain sites, or that are used with a certain frequency. It may also contain a human-readable statement of policy regarding availability of backlinks. In this case the design of the query interface is left to the server, but the server will still have information informing them of which URI backlink information is requested for.
One advantage to the HTML interface is that existing browsers can use it with minimal modification (a simple ``backlinks'' button may retrieve this and display it). For more sophisticated client programs, we believe that more elaborate and verbose methods based on RDF are appropriate. Servers that support WebDAV will require XML support, and can respond to a PROPFIND command with essentially the same response as an ordinary HTTP request for the referenced URI.
The description of response header lines follows [25], using lines of the form
prefix-location: URI mime-type [;charset]where prefix is from [25], and mime-type is one of text/html, text/rdf, or a new MIME type called x-backlinks/text discussed below. The charset is optional, and follows the MIME specification. Additional MIME types are possible as well.
Alt: URI mime-typeare used to specify further sources for backlink information. These can be used either to provide completely different sources, or in the case when more information is available from the server, a URI to fetch more or issue queries. URIs are site-specific, but examples include:
Alt: http://www.ibm.com/bl?uri=/contact.html x-backlinks/text Alt: /bl?key=76x32 text/rdf; charset=us-ascii (Plain Text) Alt: http://www.ibm.com/bl text/htmlSecond, there are lines specifying actual backlinks. These have the form:
uri count first-date last-date titleEach field except the URI can be replaced with a "-" character if the server chooses not to report it or data is unavailable. In addition, a line can be truncated at any point after the URI. Thus the simplest possible response consists of a URI. The meaning of each field is as follows:
The order of the individual backlink lines is left to the server to decide, and the client is free to use them as it wishes. The inclusion of frequency and freshness information is used to assist clients in customizing the display.
Clients may be designed to only fetch backlink information upon the interest of the user, or they may retrieve and display backlinks as the default. We imagine that backlink information will be used only on infrequent user demand, and do not wish to impose an undue burden on the network.
The HTTP extensions that we propose here will be ignored by all compliant HTTP implementations. Implementations that do not support the extension will simply suffer a minor performance degradation from constructing and transmitting the headers. Proxies may recognize incompatibilities between servers and clients, and supply appropriate translations.
Most of the server modification relates to the storage of the backlink
database and query support for backlink-enabled clients.
At the most rudimentary level, no special support is needed to provide
backlinks. The administrator simply turns on the referrer log option
in any popular web server such as
Apache, and installs a
simple CGI script that grep's the logs for the target URL.
This will not satisfy our requirements of efficiency and frugality of
space usage. At the other end, it is conceivable that fairly
sophisticated database capability will be needed to support rather
complicated queries being made to the server, e.g., ``find all inlinks
from a given site that have been followed at least 50 times in the
last 10 hours.''
We believe that web servers will continue to take on more and more characteristics of database servers in the future [12]. However, in the near term the greatest benefit for non-commercial sites of small to medium sites will probably come from the ability to make basic queries regarding inlinks. Moreover, avoiding dependence on a database will make it easier to distribute, upgrade and deploy.
We considered two candidates for integrating the backlink code with the server: modules and servlets. Apache, the most widely used server, provides a modular architecture by which additional functions can be integrated into the server through a standard API (Thau, [28]). The other option is to use server-side Java handlers, called servlets, to perform the necessary actions. With sufficient server-side capability to execute generic code associated with each page, a backlink server can be constructed with relatively little server customization. Some vendors also provide server-side scripting languages which (while mostly used for site maintenance) can be used to implement a backlink server [24].
We implemented the simple HTTP protocol extension as a module in the Apache web server. Our module performs three places in the Apache flow of processing. First, the module reports referer fields to a database, and keeps track of the number of times a link has been followed as well as the last time it was followed. Second, the module registers a special URL with the server, and supplies inlink information for urls on the server. Third, the server modifies outgoing response headers to show availability of backlink information. There are a number of configuration options, including filtering by host or path, the logging location, storage management for backlink information, and URL specification for how to retrieve backlinks. We plan to release this module through the IBM Alphaworks web site10.
Rather than use a full-fledged relational engine behind the server, we decided to use a pared-down storage manager: the Berkeley DB library, in order to encourage widespread dissemination with Apache. The current version of the database is implemented with three Berkeley DB hash tables. Keys into the tables are constructed by hashing URLs to 64-bit values. The three tables are constructed as follows:
Our server implementation is designed to simply compile backlink data from the most readily available source, but clearly there is more that could be done. Our database is populated with an access count, timestamp of last access, and URL. In addition, the server could store a full history of access, textual information, ratings, rate of change, ownership, copyright information, or many other factors. This information might be managed through a variety of tools, including crawling, automated reporting and postprocessing, or human editing. These may prove particularly useful for sites that wish to implement a specific policy involving backlink metadata. For example, the server may wish to only report backlinks that are still active, or report all links that ever existed.
At present the Apache module only supports retrieval of all links to a given page. Queries about backlink information will require more of the functionality of traditional database servers. DASL looks like a promising means to support queries on server resources, including metadata. The exact use of such queries in a client is unclear however, and the most likely mechanism may remain a traditional HTML form interface for some time to come.
It is our firm belief that backlink metadata provides a significant enhancement of information gathering from web resources. We have described a protocol by which such data can be retrieved and used by clients, and some prototype tools that will support the infrastructure. These tools support only a minimal set of policies for managing the backlink metadata, and it is natural to expect that others will develop tools to further assist in the management and use of such data. For example, the integration of backlink data into browsing tools can be done in several ways, and we encourage software developers to think of the best ways to organize and present such information.
 |
David Gibson is a PhD student at the University of California, Berkeley, where he is studying theoretical aspects of computer science, human factors, and experimental computation. He is a part-time researcher at IBM's Almaden Research Center, and partially supported through NSF grants CCR-9626361 and IRI-9712131. |
 |
Soumen Chakrabarti received his B.Tech in Computer Science from the Indian Institute of Technology, Kharagpur, in 1991 and his M.S. and Ph.D. in Computer Science from UC Berkeley in 1992 and 1996. He was a Research Staff Member at IBM Almaden Research Center between 1996 and 1999, and is now an Assistant Professor in the Department of Computer Science and Engineering at the Indian Institute of Technology, Bombay. His research interests include hypertext information retrieval and on-line scheduling of parallel servers. |
|
Kevin S. McCurley is a Research Staff Member at IBM Almaden Research Center. He received a Ph.D. in Mathematics in 1981 from the University of Illinois, and has previously held positions at Michigan State University, University of Southern California, and Sandia National Laboratories. His current research interests include information security, embedded computing, and web technologies. |
